March 22, 2023
Building a Local YouTube Assistant with LLM and Vector Databases
Learn how to build a smart local YouTube assistant using LangChain, Pinecone, and Ollama-powered LLMs.
Have you ever wished for a smart YouTube assistant that runs locally, understands your queries, and fetches the right insights instantly? Well, you’re in the right place! 🚀
Note: This blog assumes you know basic JavaScript. The required code is in the associated GitHub repo.
Table of Contents
Overview
The following steps happen in sequence once the user inputs his YouTube link and the question.
- The YouTube transcript is fetched using the Langchain library.
- The fetched transcript is broken into text chunks and indexed in Pinecone DB.
- From the Pinecone DB, the chunks relevant to the question are retrieved.
- The relevant chunks and the question are sent to the locally running LLM.
- The LLM does its magic✨ and gives the output to the user.
Prerequisites
To run this project you need 2 things apart from the GitHub repo.
1. Pinecone API key
You can sign up for a free API key using this link Pinecone DB
2. A local running LLM
For this we use Ollama, It is an open-source tool that allows users to easily run large language models (LLMs) locally on their computers. You can download ollama using the link⬇️. To learn more about ollama visit the GitHub link
Walkthrough
Once you have got the API key and installed ollama, go through the below steps.
- Clone the GitHub repo and install node packages.
git clone https://github.com/vetri15/langchain_demo
cd langchain_demo
npm install
- Rename the .env.example file and set up your environment variables.
Rename-Item -Path .env.example -NewName .env
Set-Content .env 'PINECONE_API_KEY=your-api-key'
- next run your local LLM using ollama. we will use the deepseek-r1 model. There are various parameters available, the higher the parameters the better. I could run up to 14B parameter model using my Nvidia RTX 2050 Mobile GPU paired with my Ryzen 7 processor. You may choose between 8B, 14B, and 32B models based on your PC. The below code will download and run the corresponding ollama model. Ollama will take some time to install. since DeepSeek models are a few GBs.
ollama run deepseek-r1:14b
- Once Deepseek is running. run the node.js application using the below code.
node index.js
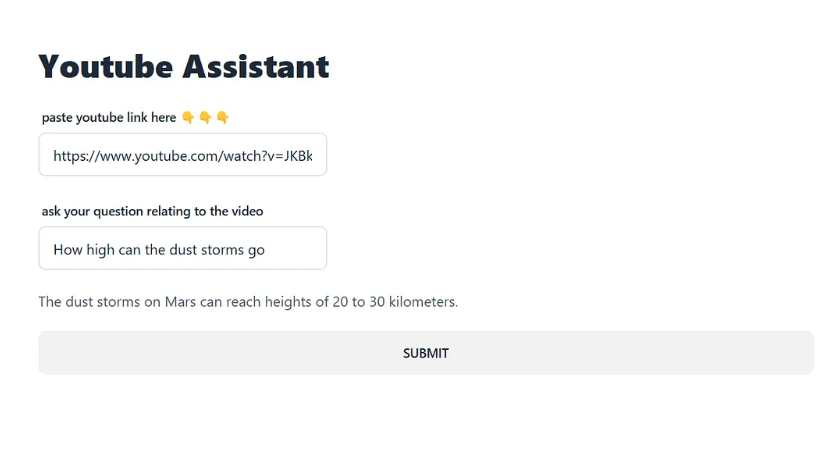
- Now paste the YouTube link and ask questions about the video.
Voila! You now have a locally running YouTube assistant.
If you have any queries, feel free to comment.☺️